
Working Papers
1. Deep Learning for Individual Heterogeneity with Generated Regressors by Adversarial Training (Job Market Paper)
Available at: Currently being updated and new version would be provided soon
Abstract
We propose a semiparametric framework that combines machine learning with generated regressors via control function to capture individual heterogeneity while addressing endogeneity and sample selection bias in complex econometric models. This approach models individual heterogeneity through high-dimensional observable characteristics, with generated regressors supporting the control function to manage endogeneity or sample selection bias flexibly across various economic structures. Leveraging a tailored deep learning architecture, our framework integrates control functions and parameter functions seamlessly, enabling its adaptation to diverse econometric models. Using adversarial training, we achieve sup-norm convergence rates of parameter functions and control function at the optimal min-max rate, which enhances robustness and yields valid inferences for inferential structural parameters in high-dimensional settings. Extending the Double Machine Learning (DML) approach, we incorporate endogenous components and establish a new influence function that directly includes generated regressors, broadening the framework’s applicability across econometric models. With automatic differentiation in PyTorch, the influence function applies directly to data, streamlining inference and supporting various structural parameters without additional calculations. This integration makes the framework particularly useful in applied settings where individual heterogeneity and endogeneity are critical, such as personalized policy-making, targeted economic interventions, and customized optimizations in technology. Our simulations demonstrate superior performance, validating this framework’s practical use in econometric analysis where heterogeneity and endogeneity are key considerations.
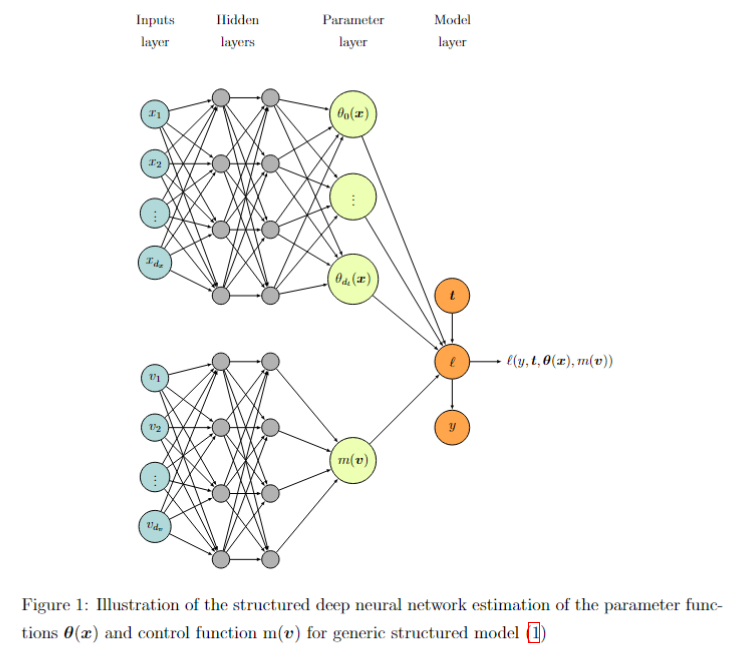
2. Estimating Partial Effects Using Machine Learning
Abstract
In this paper, we explore the use of machine learning techniques for estimating partial derivatives, which is a critical step towards understanding causal relationships in econometric analysis. By leveraging modern machine learning methods, such as tree-based models and deep neural networks, we assess their effectiveness in recovering regression functions and estimating partial derivatives. We introduce a novel tree-based model, Boosting Smooth Transition Regression Trees (BooST), and compare its performance with other models, including Boosting of Symmetric Smooth Additive Regression Trees (SMARTboost) and deep neural networks (DNNs). Simulations, based on the well-known Friedman data generating process (DGP), demonstrate the superiority of BooST in estimating partial effects across various signal-to-noise environments and in the presence of redundant variables. The empirical applications, including the study of Engel curves, further highlight the ability of BooST to outperform other machine learning models in accurately estimating partial derivatives. Our findings suggest that BooST provides a powerful tool for nonparametric regression and causal inference, especially in econometric contexts where accurate estimation of marginal effects is crucial.
3. A Comparative Study of Machine Learning Models for Prediction: Insights from Tree-Based Models and Deep Neural Networks
Abstract
The growing influence of machine learning (ML) and big data technologies has significantly reshaped many scientific disciplines, including econometrics. This paper conducts a detailed comparative analysis of various tree-based and deep learning models, focusing on their prediction capabilities. The models examined include neural networks (e.g., MLP, ResNet), and several advanced tree-based models (e.g., Boost- Smooth, SMARTboost and Random Forest). Additionally, we explore different prediction combination techniques to evaluate whether combining predictions from multiple models enhances predictive accuracy. Using simulations from the comprehensive data generating processes (DGP), we systematically compare the performance of these models under varying levels of noise and the presence of irrelevant features. Our findings reveal that tree-based models like SMARTboost and BooST demonstrate robust performance, particularly in low signal-to-noise scenarios, where they often outperform neural networks. Moreover, the inclusion of ensemble methods, such as median and simple average combinations, further improves prediction stability. Two real-world economic applications—Engel curve prediction and stock price crash risk prediction—highlight the practical implications of our analysis, showing the advantages of tree-based methods in capturing both linear and nonlinear data structures, while DNNs struggle in noisy and nonlinear environments. Our study emphasizes the need for careful model selection and the potential benefits of hybridizing prediction models for complex data tasks.
Publications & Conference Papers
- Comparing Methods for Continuous Treatment (with Meng Xu), CODE@MIT, 2023 Presented at CODE@MIT, 2023.
Available at: Download PaperAbstract
This paper presents a comparative study of two advanced methodologies for estimating the effects of continuous treatments on outcome variables in large-scale tech applications. We focus on dose-response curves and marginal effects to address various business scenarios, such as the impact of ad frequency on user conversions, geolocation campaigns on local engagement, and latency on app performance. Our investigation centers around two promising approaches: entropy balancing for continuous treatment and double/debiased machine learning (DML). Using semi-synthetic data based on Snapchat user behavior, we evaluate these methods' performance in terms of scalability, flexibility, and precision in handling high-dimensional, non-linear relationships between outcome variables, continuous treatments, and confounders. The study finds that tree-based machine learning models, particularly XGBOOST and Boostsmooth, outperform balancing approaches in estimating dose-response curves, while the balancing method performs best for marginal effect estimation. Notably, our findings also challenge the efficacy of the kernel-based selection model in the double machine learning process, prompting a reconsideration of its utility in real-world applications.
- Does “Too-Connected” Network of Shareholders Exacerbate Crash Risk? (with Haiqiang Chen, Yang Chen and Muqing Song), China Economic Quarterly (经济学季刊), 2023(03): 1070-1087. Available at: Download Paper
Abstract
Using quarterly data from the top 10 largest shareholders of A-share stock markets from 2003 to 2018, we construct a network of influential shareholders. Our findings reveal that firms with more interconnected shareholders face higher crash risk, especially when dominated by financial institutional shareholders or those with higher shareholding ratios. In contrast, state ownership and robust corporate governance significantly mitigate this risk. Mechanism analysis shows that firms with higher network centrality tend to have a higher goodwill-to-market value ratio, a greater proportion of related-party transactions to total assets, and larger M&A premiums, yet exhibit lower corporate governance transparency. These results suggest that overly connected shareholder networks may encourage tunneling behavior, exacerbating the crash risk for listed companies.